Stat 5102 (Geyer) Midterm 1
The joint density is
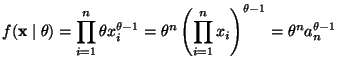
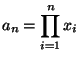
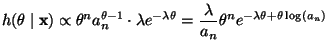
Equation (11.36) in the notes gives the mode of the gamma distribution: shape parameter minus one over scale parameter, in this case
By Example 11.2.4 in the notes, the posterior
distribution is
Normal![]() where
where
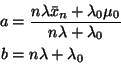
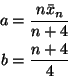
The HPD region for a normal posterior distribution is
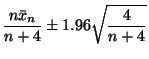
The likelihood for ![]() is
is
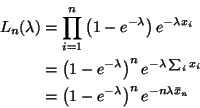
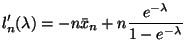
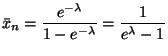
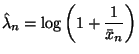
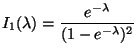
A 95% C. I. for ![]() is
is
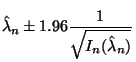
Equation (10.37) in the notes gives the log likelihood for the two-parameter
normal. To convert to the log likelihood for this problem we need to plug in
![]() for both
for both ![]() and
and ![]() giving
giving
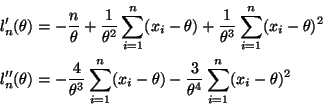
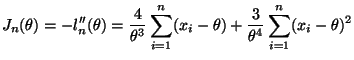
The solution given above is perhaps the easiest. Another contender for the easiest expands the binomial in (1) giving
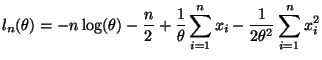
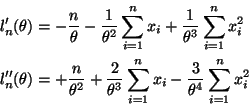
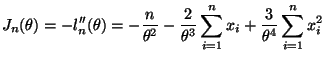
The deriviatives are a bit easier and the expectations are a bit harder than the first solution, but both are fairly easy.
The alternate solution that uses the empirical parallel axis theorm to ``simplify'' (1) giving
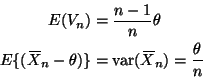
The alternate solution that expands the binomial in (2) giving
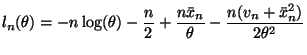
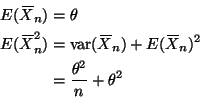
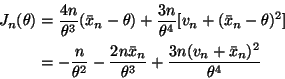
Example 9.5.4 in the notes gives the math for this problem.
The natural estimates of ![]() and
and ![]() are
are
![]() and
and
![]() .
The natural test statistic is
.
The natural test statistic is
![]() divided by its
standard error (estimated standard deviation). As explained in the example,
the natural choice for the standard error when we assume
divided by its
standard error (estimated standard deviation). As explained in the example,
the natural choice for the standard error when we assume ![]() uses the pooled estimate of
uses the pooled estimate of ![]() (and
(and ![]() ), which is
), which is
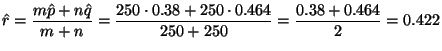
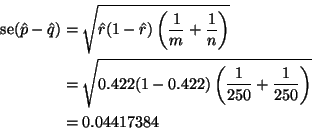
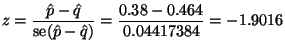
Not part of the question, but of interest in real life is the interpretation
of the ![]() -value. According to conventional standards of evidence, this
is a ``statistically significant'' result because
-value. According to conventional standards of evidence, this
is a ``statistically significant'' result because ![]() . Since
. Since ![]() is not that far below .05, this is not absolutely compelling evidence of
effectiveness of the new treatment, but it is fairly compelling.
is not that far below .05, this is not absolutely compelling evidence of
effectiveness of the new treatment, but it is fairly compelling.
The pooled estimator of ![]() and
and ![]() under
under ![]() is just the number of
deaths in both groups divided by the number of subjects in both groups,
so is also
is just the number of
deaths in both groups divided by the number of subjects in both groups,
so is also
An asymptotically equivalent way to do the problem
(almost no difference when ![]() and
and ![]() are large and
are large and ![]() is true)
uses the standard error estimate
is true)
uses the standard error estimate
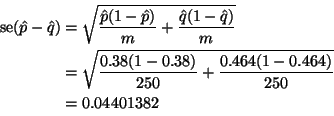
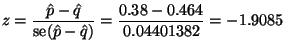
Note that this method is not recommended in real life, not because there is anything wrong with it, but because it's not the method taught in intro statistics books and hence people will argue.
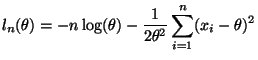
![$\displaystyle l_n(\theta) = - n \log(\theta) - \frac{n}{2 \theta^2} \sum_{i = 1}^n [ v_n + (\bar{x}_n - \theta)^2 ]$](img49.gif)